5.10 Diff-in-diff analysis
Diff-in-diff is a widely used form of analysis where the effect of a "treatment" is analysed by comparing the change in the average value for a continuous/rankable response variable before/after the time of treatment. This is done for two groups:
-
Treatment group
-
Control group
Finally, the difference between the two groups is calculated.
The following preparatory steps must be followed before running a diff-in-diff analysis:
-
Create a panel dataset through the command
import-panelor by converting from "wide" format to "long" format through the commandreshape-to-panel. -
Create a group variable with the value 1 for the treatment group and 0 for the control group.
-
Create a treatment variable that is set to 0 for all times before the treatment time, and 1 for all times starting from the treatment time.
After following steps 1. - 3. the command regress-panel-diff is
used.
The dependent variable is listed first. It must be continuous or rankable. The group and treatment variables need to be listed as numbers 2 and 3. This is a prerequisite for the analysis to be carried out correctly. Other independent variables are listed at the end (optional).
The result from regress-panel-diff shows a standard panel regression table with model measures and coefficient values. The diff-in-diff value (so-called ATET value - average treatment effect of the treated) corresponds to the coefficient value of the interaction term for the two dummy variables which indicate respectively group and treatment.
Example:
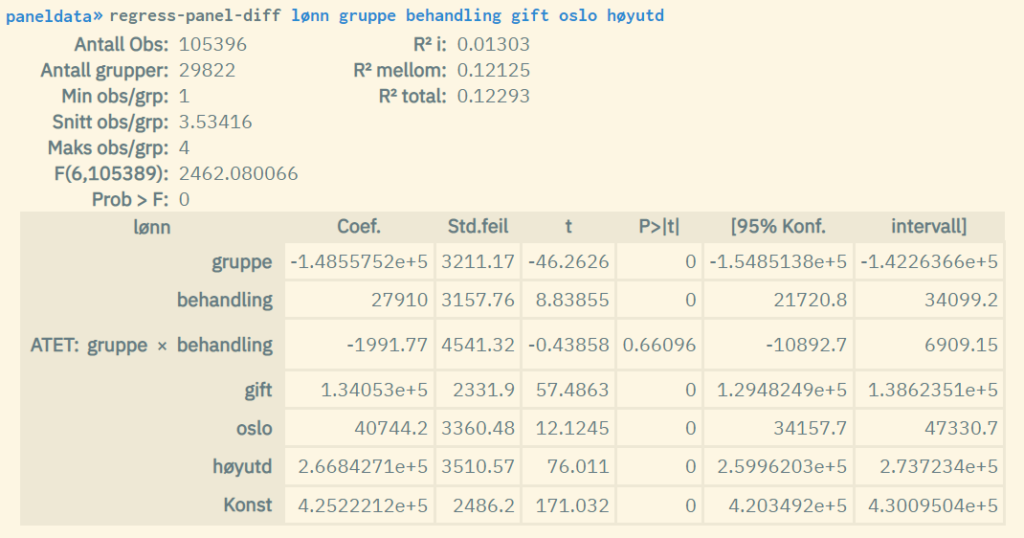
The command regress-panel-diff is equivalent to running regress-panel with the option pooled where the group and treatment variables are included as interaction terms as well as separate dummies (use the characters ## to express this).
Example:
regress-panel-diff salary group treatment married oslo high_edu
gives the same result as
regress-panel salary group##treatment married oslo high_edu, pooled
The following options are available for regress-panel-diff:
-
level(): Define a significance level other than the default value of 95 (5% significance level) -
robust: Robust standard deviations -
cluster(): Cluster estimation
The command help regress-panel-diff generates more information about
the available options.
Time (e.g. factor terms such as i.year) should not be included in
regression-panel-diff models, as you risk obtaining 100% equal variance for the treatment variable compared with the dummy terms linked to the years from and including the time of treatment. The coefficient estimates for the variables/terms involved will then be incorrect as a result.
Example on data adaptation for diff-in-diff analysis
If you create a panel dataset using import-panel, measurement dates are processed with the UnixTime format, and you must then use the function year() to extract /refer to the year, as in the example above:
replace treatment = 1 if year(date@panel) >= 2020
If you instead use reshape-to-panel to create a panel dataset, you are the one who controls the value format for the measurement dates through the use of suffixes on the variables (usually two-digit or four-digit years), and you must then take care to adapt the replace expression so that it matches the format of date@panel. If you use a suffix that indicates a four-digit year (YYYY), this will also be the format of the values for date@panel. Then you should not use year() since this is only intended for use with UnixTime formats. In this case, you must refer to the year as follows:
replace treatment = 1 if date@panel >= 2020